




Function Spaces with Countable Bases
Recommended background: basic calculus (continuity, derivatives, and integrals), and an idea of countable vs. uncountable.
Piecewise Linear Approximation
Consider the set C(I) of continuous functions from the interval I = [0,1] to the real line \mathbb{R}. Intuitively, there are a lot of these functions. Let’s try and get a handle on how many there are.
First of all, this set is a vector space over the real numbers, because if f,g : I \to \mathbb{R}, then we can define \alpha f + \beta g : I \to \mathbb{R} for any \alpha,\beta \in \mathbb{R}.
Now, for any n \in \mathbb{N}, we can embed \mathbb{R}^{n+1} into C(I) in the following way. For v \in \mathbb{R}^{n+1}, define \xi_n(v) : I \to \mathbb{R} by letting \xi_n(v)(k/n) = v_k and then defining \xi_n(v)(x) for x \neq k/n by linearly interpolating between the two closest points. Because we are linearly interpolating, \xi_n is a linear map. This shows that the dimension of C(I) is greater than any natural number.
On the other hand, given any continuous f : I \to \mathbb{R}, we can approximate f arbitrarily closely with functions that are in the image of these embeddings. Below is an illustration of a sine function and two approximations, one with n=4, the other with n=8.

You can imagine that as n gets larger, it is harder and harder to tell the difference between \sin(x) and a piecewise linear approximation. In fact, the “real” sine function on that graph is just a very good piecewise linear approximation; you just can’t tell because once n is larger than the width of the graph in pixels, you can’t get any closer to the actual function.
This is very unsurprising, and you are probably wondering why I am going on about this. The answer is that the idea that such a seemingly large space (C(I)) can be approximated arbitrarily well by finite dimensional spaces \mathbb{R}^n is an idea that shows up again and again and again in different forms, and it is useful to first look at the case in which it is obvious before looking at the cases in which it is not obvious. It is also worth noting that this is not true for discontinuous functions; a discontinuous function can be so badly behaved that you can’t approximate it well with functions of the form \xi_n(v). For instance, the function which is 1 at every rational number and 0 at every irrational number cannot be approximated in this way.
A Theory of Approximation
We want to give a mathematical definition for this phenomenon of “arbitrarily close approximation”. Let’s start off with a (hopefully) familiar example: the rationals and the reals. Suppose that you are a cheap mathematician and you can’t afford to use real numbers, and I am a sketchy engineer in a trench coat promising you that I can get you real numbers for “less dollars”. I open my trench coat, and inside is every rational number.
Understandably, you are a bit skeptical of my claim that I can get you real numbers. So you ask me a question: “What if I need to measure the area of a circle? I learned in school that the area of a circle is \pi r^2, how am I going to calculate that without using the irrational number \pi?”
I respond: “Look mister. Why are you so picky? You want \pi? I give you 355/113. Is just as good.”
You consider my offer before telling me you are worried that your professor might ask for very precise answers on the homework.
I say: “How precise you want? You tell me, and I get you some nice numbers.”
“Do you have anything that is within one over a billion?”
“Hoo boy tough customer. But I can do it.” I rummage around in my trenchcoat. “OK, here you go: 3.1415924535. Just for you, I make approximation that is accurate to one over ten billion. And because you are such a special guy, I also give you e: 2.7182818284.”
You ponder again, but just as you are about to say something, I interupt you. “Hey,” I say, “I’m a busy guy; I don’t got all day. But I’ll make you a deal. I give you 3.1415924535 now, and if you need more precise, you call me up any time and I got you covered.” Before you can say anything else, I retreat back into the shadowy alleyway that you found me in, and you don’t particularly want to follow me.
The point of this dialogue is to hammer home the point that for any number x \in \mathbb{R}, and any \epsilon> 0, you can call up a sketchy trenchcoat guy and get a number n/m \in \mathbb{Q} (n and m are integers) such that |x - n/m| < \epsilon. This is what it means to say that the rationals are “dense” in the reals.
However, there is a stronger point that we can make here. If I keep calling up the sketchy trenchcoat man and ask for better and better approximations, then I can eventually “prove” that any two numbers x and y are different (assuming that they actually are different). This is because I will eventually ask for approximations to x and y that are within |x - y|/4 of x and y respectively, and these approximations will necessarily differ by more than |x - y|/2. The only way that this never happens is if x = y. Therefore, an infinite sequence of better and better rational approximations uniquely defines a real number.
Similarly, you can imagine that for C(I) there is another sketchy trenchcoat man who gives you functions of the form \xi_n(v). The problem is, unlike in \mathbb{R} where we had a clear measure of distance between any two numbers, it is unclear what we mean by “two functions are < \epsilon away from each other” for C(I).
One way of defining this distance is by saying two functions f and g in C(I) are < \epsilon away from each other if |f(t) - g(t)| < \epsilon for all t \in I. Colloqually, this can be expressed by saying that f and g are “at most” \epsilon away from each other.
Now we have the technology to say that functions of the form \xi_n(v) are dense in C(I). Hopefully this should be intuitive, although not immediately clear how to prove this. For this post, we will take this on faith.
Again, we have the curious property that a continuous function is uniquely defined by an infinite sequence of better and better approximations of the form \xi_n(v). One consequence of this is that in order to approximate a continuous function arbitrarily closely, it suffices to only know the values of that continuous function at rational numbers, because these are the only values that are captured by the \xi_n(v). This is surprising! A priori, you can think of a function from [0,1] to \mathbb{R} as a table with uncountably many real numbers in it. However, this says that you only need a table with countably many real numbers! We will see this pattern repeat over and over in the rest of this blog post.
More Dense Sets of Functions
However, the collection \xi_n(v) is far from being the only set of functions that is dense in C(I). Here’s another interesting set of functions: functions of the form
f(t) = \sum_{k=-N}^N A_k \mathrm{e}^{2 k \pi i t}
Intuitively, this makes no sense. If some guy promised to give you any continuous function, and then opened his trench coat to reveal only functions of that form you would think that he was high on something. And you would be right, because f(0) = f(1), so not all functions are accounted for. But if he said that any function f : I \to \mathbb{R} such that f(0) = f(1) by a function in that form, then he might be sober.
You may have noticed something funky, which is that f(t) might be complex. However if A_k is the complex conjugate of A_{-k}, then you can check that in fact f(t) is real. We can then write f(t) as a sum of sines and cosines. However, trigonometric identities are annoying, and exponential identities are easy, so complex numbers it is!
To illustrate the idea behind approximation with functions of the above form, here is a neat GIF I picked up from Wikipedia that shows increasingly better approximations to a square wave.
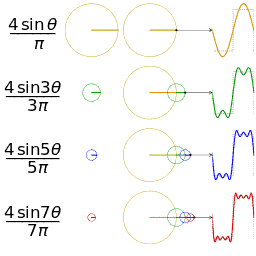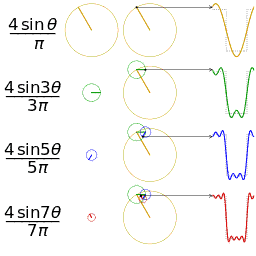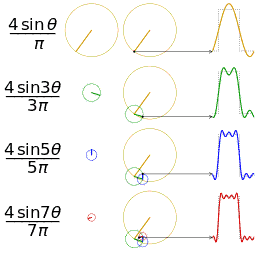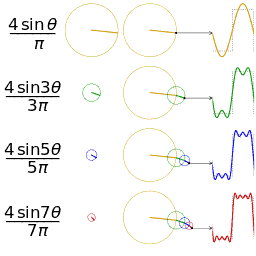
Each circle in that picture represents one term of the sum, i.e. A_k\mathrm{e}^{2 k \pi i t} for some k. When you take the imaginary part of \mathrm{e}^{2 k \pi i t}, you get \sin(2 k \pi t), which is what is labeled in the picture (in the picture they don’t have the factor of 2 \pi because the domain is [0,2\pi] instead of [0,1]). Finally, stacking the circles represents addition of the terms.
You should stare at this GIF until it makes sense to you and relates to what I am saying.
For convenience, from now on I will write \mathrm{e}^{2 k \pi i t} as c_k(t) (c stands for “circle”).
Now, here’s a question. Suppose you wanted to be the sketchy trenchcoat guy for harmonic functions (which is the Official Math Word for the type of function I wrote above). I give you a function that you are going to approximate. How do you find the coefficients that you need?
Before we answer that, let’s answer an easier question. Suppose that f is a harmonic function. Can we rederive those coefficients A_k from f? It turns out that this is surprisingly easy. I’m going to just derive some nice little identies involving c(t).
\int_0^1 c_1(t) dt = 0 Reasoning: If we go in a circle, opposite points on the circle cancel out.
For k a non-zero integer, \int_0^1 c_k(t) dt = 0 Reasoning: If we go in k circles, each circle has integral 0, so the whole thing has integral 0.
c_{k}(t)c_{k’}(t) = c_{k+k’}(t) Reasoning: Look back at the definition of c(t), and use e^x e^y = e^{x+y}.
\int_0^1 c_{k}(t)c_{k’}(t) dt = \begin{cases} 1 & \text{if}\: k + k’ = 0 \\ 0 & \text{otherwise} \end{cases} Reasoning: Apply 2 and 3.
We now apply these identities in the following equation, where f(t) = \sum_{k=-N}^N A_k c(kt).
\int_0^1 c_{-k}(t) f(t) dt = \sum_{k’=-N}^N A_{k’} \int_0^1 c_{-k}(t)c_{k’}(t) dt = A_k
That last equation is pretty dense, so don’t worry if it doesn’t make immediate sense. Stare at it for a bit.
Anyways, with this in mind, I claim (without proof) that in order to get a good approximation for f, the sketchy trenchcoat guy for harmonic functions just needs to pick a large N, compute
A_k = \int_0^1 c_{-k}(t) f(t) dt
for k = -N,\ldots,N, and then hand over the function
f_{\mathrm{approx}}(t) = \sum_{k=-N}^N A_k c_k(t)
Showing that this is a good approximation to any continuous f with f(0) = f(1) requires more work than you or I really want to do right now, so you are just going to take this on faith.
To signify that this approximation gets arbitrarily good as N goes to infinity, we write
f(t) = \sum_{k=-\infty}^\infty A_k c_k(t)
This looks like something you may have seen before in Linear Algebra: writing a vector as a linear combination of basis elements. Unfortunately, \{c_k\} is not literally a basis for the space of continuous functions, because part of the definition of a basis is that you must be able to write any vector as a finite linear combination of basis elements. However, it acts like a basis in a lot of ways, and it’s useful to think of it in that way, and mathematicians are terrible with consistent terminology, so we call it a basis anyways. We call this basis the “Fourier basis”, and we call the infinite series above a “Fourier series.”
This opens the natural question: are there other bases for this space? The answer is yes, there are many, many bases for this space.
Moreover, even for spaces that are intuitively “larger”, such as the space of functions from a disc or a cube, there are still countable bases.
And in fact, if a function has a finite number of discontinuities, it can still be approximated by series of this form: we saw this earlier with the square wave.
Why do we care about being able to represent continuous functions with a countable basis? Well, one reason is that if we can only measure to a certain precision, then we can forget anything above that precision. A famous application of this is in audio recording. In an audio signal over a interval that is a second long, it turns out that our ears can’t pick out any of the coefficients of c_n for n > 44,000. Therefore, for perfect reproduction of a second of audio signal to human ears, you only need to store 44,000 numbers.
In general, in signal processing it is much easier to work with the coefficients of a Fourier series than it is to work with the signal itself. One common operation that you end up implementing a lot is filtering out high frequency or low frequency sound, and this can be done by literally scaling down the coefficients for high n or low n.
But I want to convince you that this idea of representing a continuous function by a countable collection of numbers is larger than Fourier series, so we are going to move on to another topic.
More Uses for Bases
You may be familiar with this example from calculus class. Any function that is analytic at 0 can be approximated arbitrarily closely near 0 by functions of the form
\sum_{n=0}^N a_n \frac{x^n}{n!}
Actually, this is kind of cheating, because the definition of analytic function is that they can be approximated arbitrarily closely with a function of that form. However, it turns out that any function that you can define by a sum, product, or composition of analytic functions is analytic, and all the basic functions you can think of are analytic as long as they are defined at 0 (all polynomials, \sin(x), \cos(x), e^x, \frac{1}{1-x},…). And this is very useful: the sketchy trenchcoat guy in a computer that calculates \sin for you is actually just using the power series expansion for \sin for a large N (in addition to using rational approximations for numbers: approximations on top of approximations!)
And Taylor series are sometimes much more convenient to work with than regular analytic functions. For one, it is always easy to integrate a power series, because we know how to integrate polynomials. It is a little known fact that after inventing the calculus, Newton preferred to only work with power series because he couldn’t be bothered to do nasty integrations (and I don’t blame him: integration by parts is No Fun!)
On the other hand, sometimes analytic functions are much easier to work with than power series! This is the idea behind generating functions. Suppose we are interested in calculating the terms of some sequence a_n. Well, sometimes it turns out to be much easier to calculate what the function \sum_{n=0}^\infty a_n \frac{x^n}{n!} is, and then derive the a_n from that! This seems very weird the first several times you do it, but eventually seems second nature. To learn more about this, check out the oddly named book “generatingfunctionology”, available for free online.
It turns out that Fourier series can be used in the same way. Suppose there is some bug that is jumping around randomly on the integer line. Then we have some probibility distribution p(n,t) for n \in \mathbb{Z}, t \in \mathbb{R}_{\geq 0} which represents the probability that the bug is at position n at time t, and we want to compute this probability distribution. Well, it turns out that, depending on how the bug is jumping around, we can write a differential equation for p(n,t) that looks something like
p’(n,t) = \sum_{k=-\infty}^\infty H_{kn} p(k,t)
If we think of p(-,t) as a vector then this can also be written as
p’(-,t) = H p(-,t)
because the earlier equation is the definition of matrix multiplication. Now, this is an ordinary differential equation with infinitely many terms, and is rather difficult to solve. However, if we replace p(-,t) with
\hat{p}(t) = \sum_{n=-\infty}^\infty p(n,t) c_n(x)
and we can cook up some operator \hat{H} such that
\hat{H}\hat{p}(t) = \sum_{n=-\infty}^\infty \left(\sum_{k=-\infty}^\infty H_{kn} p(k,t)\right) c_n(x)
then we have transformed the ordinary differential equation in countably many variables into a partial differential equation in two variables, and sometimes this can be solved more easily. I don’t expect you to fully understand this based on my sketchy explanation, but the point is that being able to move fluidly between “continuous” and “countably infinite” representations is very useful.
One Last Bit of Philosophy
As mortals, we are only able to access the finite directly. In order to talk about infinity, we need to sneak up on it by using our finite tools. One way to do this is by saying “this symbol, right here, represents something that is infinite.”
However, another more satisfying way that we can make the infinite have meaning is by saying that the infinite is the “final” approximation when we have an algorithm for making arbitrarily good approximations.
Ultimately, I think that this is the only way to really work with infinity. What would it even mean for a human to perceive a truly discontinuous function, a function that took on a random value at every point? Such a function cannot exist in our world, and cannot exist in our brain.
And once we have accepted this, it’s trenchcoat men all the way down.